ガバメントクラウドを想定した複数の VPC でエンドポイントを集約して共有する方法
これまで書いてきた通り、ガバメントクラウドの AWS 環境を使う地方自治体は基幹業務システムを複数の AWS アカウント、複数の VPC で運用することが想定されます。
基幹システムの VPC はプライベートサブネットのみの閉域で運用されるため、運用に必要な AWS の各サービスを使うには、各サービスのエンドポイントを VPC に作り、エンドポイント経由で各サービスにアクセスする必要があります。
ここで、複数の VPC それぞれにエンドポイントを作ると、費用が無駄にかかる上、管理コストも増えてしまいます。
基幹システムの VPC 同士は連携の都合上 Transit Gateway などで相互にルーティングできることがほとんどのため、エンドポイントは一つの VPC にまとめてしまい、他の VPC からはそのエンドポイントへルーティングしてアクセスできるようにすれば、各 VPC に個別にエンドポイントを作る必要がなくなります。
そこで、次の方法で一つの VPC に作ったエンドポイントに対し、別の VPC のリソースからアクセスし、AWS サービスを使用できるようになることを検証してみます。
なお、エンドポイントをまとめる VPC は共有リソース VPC という扱いとし、共有リソース VPC はアプリケーションを載せる VPC とはアカウントを分けて運用する想定(いわゆるネットワークアカウント)とするので、二つのアカウントの VPC でエンドポイントを共有できるかの検証になります。
- 検証作業の概要
- 検証環境の構成図
- 事前準備
- Session Manager のエンドポイントをアカウント A で作成
- Route 53 のプライベートホストゾーンをアカウント A で作成
- アカウント A の VPC の EC2 から Session Manager に接続
- アカウント A の VPC に Route 53 インバウンドエンドポイントを作成
- アカウント B の VPC の DHCP オプションセットの DNS の設定を変更
- アカウント B の VPC の EC2 から Session Manager に接続
- まとめ
- 参考
検証作業の概要
- 二つの AWS アカウント(アカウント A、B)つ用意し、それぞれのアカウントにプライベートサブネットのみを持つ VPC を一つ立てる。それぞれの VPC には検証用の EC2 インスタンスを立てる。
- それぞれの VPC は Transit Gateway で接続し、相互のプライベートサブネット同士がルーティングできるようにする。
- アカウント A の VPC にのみ Systems Manager の Session Manager のエンドポイントを作成する。
- アカウント A の Route 53 にプライベートホストゾーンを作成し、アカウント A の VPC に関連付ける。
- 作成したプライベートホストゾーンに Session Manager のエンドポイントに対するエイリアスのレコードを登録する(これでアカウント A の VPC 内からのみ、Session Manager のエンドポイントの名前解決ができアクセスできるようになる)。
- アカウント A の Route 53 インバウンドエンドポイントをアカウント A の VPC に作成する。
- アカウント B の VPC の DHCP オプションセットを変更し、DNS サーバの IP アドレスをアカウント A にある Route 53 インバウンドエンドポイントの IP アドレスに変更する。
- アカウント B の VPC にある EC2 の DNS 参照先がアカウント A の Route 53 インバウンドエンドポイントに向いていることが確認する(これでアカウント B の VPC 内からも Session Manager のエンドポイントを名前解決できるようになる)。
- アカウント B の VPC にある EC2 から Session Manager に接続する(今回のゴール)。
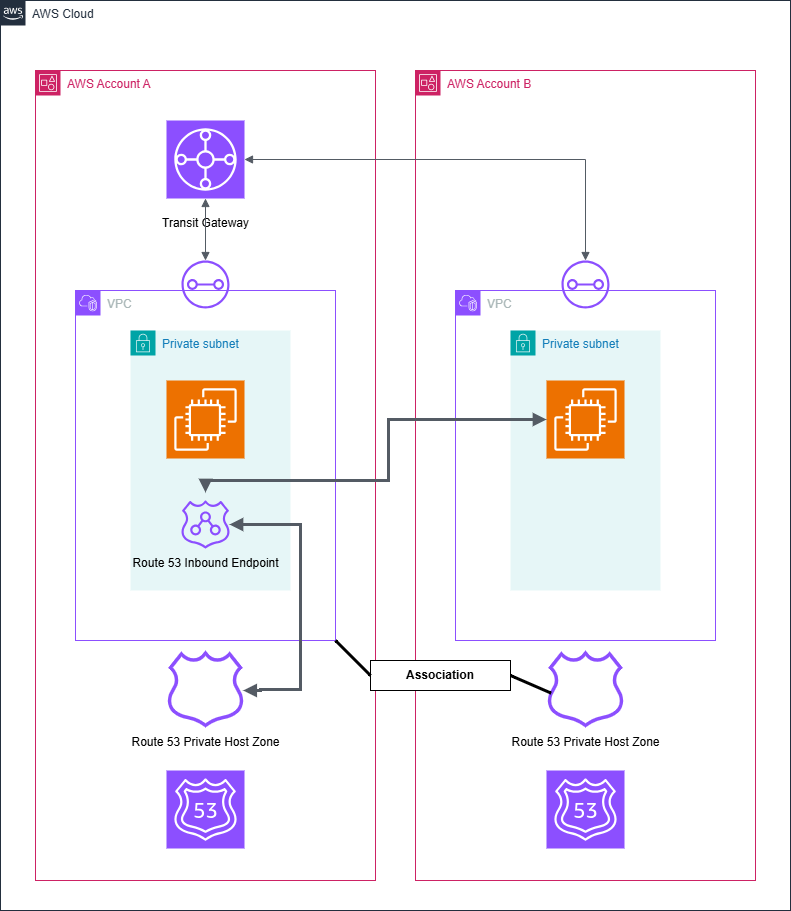
検証環境の構成図
構成図は以下のとおりです。最終目標はアカウント B の EC2 からアカウント A の VPC にある Session Manager のエンドポイントにアクセスすることです。

事前準備
まずはアカウント A、アカウント B それぞれでプライベートサブネットのみの VPC を作成し、適当に EC2 インスタンスを立てます。そしてこの二つの VPC を Transit Gateway で接続するのですが、Transit Gateway の接続方法は以前に書いた記事にまとめています。
それでは実際の作業を開始します。
Session Manager のエンドポイントをアカウント A で作成
アカウント A の VPC のマネジメントコンソールから、「エンドポイント」→「エンドポイントの作成」に進み、ssm のエンドポイントを選択します。

エンドポイントを作成する VPC を選択します。また、「DNS 名を有効化」は通常チェックしますが、今回の用途の場合、敢えてチェックを外します。これはプライベート DNS 名を有効にしてエンドポイントを作成してしまうと、エンドポイントを作成した VPC 内からしか名前解決できないためです。余談ですがこの手順は AWS Advanced Network (ANS) 認定試験で問われた記憶があります。

エンドポイントにはセキュリティグループをアタッチする必要があります。事前に TCP 443 番ポートを許可するセキュリティグループを作っておき、これをアタッチします。

以上の設定でエンドポイントを作成します。続いて、ssmmessages、ec2messages のエンドポイントも ssm のものと同じ手順で作成します。
Route 53 のプライベートホストゾーンをアカウント A で作成
このままでは Session Manager の名前解決ができずアクセスできないため、Route 53 のプライベートホストゾーンに Session Manager のエンドポイント名をレコード登録します。
アカウント A の Route 53 のマネジメントコンソールから、「ホストゾーン」→「ホストゾーンの作成」に進みます。アカウント A の VPC に関連付けてプライベートホストゾーンを作成します。

作成したプライベートホストゾーンに、Session Manager のエンドポイント名のレコードを追加します。レコードタイプは A レコードで、「エイリアス」を有効にし、「トラフィックのルーティング先」を「VPC エンドポイントのエイリアス」とし、ssm のエンドポイントを選択してレコードを作成します。

同様の手順で、ssmmessages、ec2messages のプライベートホストゾーンをそれぞれ作成します。ちなみにホストゾーン一つにつき月額 0.5 USD かかるので注意。
アカウント A の VPC の EC2 から Session Manager に接続
プライベートホストゾーンの作成により、アカウント A の VPC 内からは Session Manager のエンドポイントを名前解決できるようになり、サービスも使用できるようになります。以下の画面は Session Manager 経由でアカウント A の VPC にある EC2 に SSH し、Session Manager のエンドポイントを名前解決した結果です。プライベートサブネットの IP アドレスが返ってくることが確認できています。

逆にアカウント B の EC2 から Session Manager に接続できるでしょうか?

現時点ではまだ接続できません。なぜなら、アカウント B の EC2 はプライベートサブネットにあり、インターネットゲートウェイには接続されておらず、Session Manager の VPC エンドポイントもないので、接続することができない状態です。
ここから、この EC2 が名前解決にアカウント A の Route 53 インバウンドエンドポイントを使えば、アカウント A のプライベートホストゾーンにあるアカウント A の VPC に作成した Session Manager のエンドポイントの IP アドレスを引くことができるようになり、結果アカウント B 側の VPC に Session Manager のエンドポイントを作成しなくても Session Manager に接続されることを試してみます。
アカウント A の VPC に Route 53 インバウンドエンドポイントを作成
インバウンドエンドポイントの作成は Route 53 のマネジメントコンソールから行います。手順は以前に書いた記事にまとめています。
インバウンドエンドポイントが作成できたら、この IP アドレスを控えておきます。この後、アカウント B の DHCP オプションセットに DNS の IP アドレスとして設定するためです。
アカウント B の VPC の DHCP オプションセットの DNS の設定を変更
アカウント B の VPC のマネジメントコンソールから「DHCP オプションセット」→「DHCP オプションセットを作成」に進みます。「ドメインネームサーバー」の値に先ほど控えたアカウント A の Route 53 インバウンドエンドポイントの IP アドレスを設定します(本来 Route 53 インバウンドエンドポイントは 2 個以上あるのですが、今回は検証のため 1 個だけ設定しています)。

DHCP オプションセットが作成できたら、同じくマネジメントコンソールから VPC を選び「VPC の設定を編集」に進みます。「DHCP 設定」から「DHCP オプションセット」に先ほど作成した DHCP オプションセットを選択します。変更された DHCP 設定で EC2 が DNS の設定を受け取るため、手っ取り早くマネジメントコンソールから EC2 を再起動します。

アカウント B の VPC の EC2 から Session Manager に接続
EC2 の再起動が終わったら、アカウント B の EC2 のマネジメントコンソールから「接続」→「セッションマネージャー」を確認してみます。

今度はセッションマネージャーに接続できる状態になっていることが分かりました!それでは Session Manager 経由の SSH でアカウント B の VPC にある EC2 に乗り込んでみます。

(アップデートしてないなこいつ……)という突っ込みは一旦置いといてもらって、別 VPC にあるエンドポイント経由でプライベートサブネットの EC2 から Session Manager に接続できることが確認できました!
最後にアカウント B の EC2 から Session Manager のエンドポイントを名前解決してみます。

DHCP オプションセットで設定したアカウント A の Route 53 インバウンドエンドポイントが参照先 DNS サーバに設定されており、アカウント A の VPC のプライベートサブネット内の IP アドレスが返ってきていることが確認できました。
まとめ
プライベートサブネットしかない複数の VPC でエンドポイントを使いたい場合、一つの VPC にエンドポイントを集約することができます。
具体的には、エンドポイントを作成した VPC と関連付ける Route 53 プライベートホストゾーンにエンドポイントへのエイリアスをレコード登録し、Route 53 インバウンドエンドポイントなどの方法でプライベートホストゾーンの名前解決を他の VPC と共有できれば、後は Transit Gateway などの方法で VPC 同士がルーティングできるようにすることで実現できます。
実はわざわざ Route 53 インバウンドエンドポイントを作らなくても、今回の検証であればアカウント A のプライベートホストゾーンをアカウント B の VPC に関連づけることで実現できます。しかし、ガバメントクラウドにおける地方自治体の基幹業務システムの運用の場合、オンプレミスとの連携もあり Route 53 インバウンドエンドポイントを作成して他の VPC と共有していることが多いかと思いますので、敢えてこちらの方法で検証しました。VPC の数が少なく、Route 53 インバウンドエンドポイントを作成するほどでもない状況であれば、単にプライベートホストゾーンを他の VPC へ関連付けてあげるだけで大丈夫です。
参考
ガバメントクラウドを想定したマルチアカウントの閉域 VPC 間を Transit Gateway で相互接続する方法
地方自治体がガバメントクラウドの AWS 環境へ基幹業務システムをリフトしオンプレミスの庁内ネットワークと接続して運用する場合、基幹業務システムはインターネットに接続できないため、庁内ネットワークから Direct Connect で AWS 環境へ接続する必要があります。
基幹業務システムは複数の VPC で運用される可能性が高いため、Direct Connect は Direct Connect Gateway に接続し、更に各リージョンの Transit Gateway に接続するのがよいかと思います。
ここで、基幹業務システムの VPC が複数の AWS アカウント(マルチアカウント)で運用される可能性があるため、マルチアカウントの VPC 間を Transit Gateway で接続することを考える必要がありそうです。
実際にマルチアカウントで Transit Gateway を共有して相互接続するよう使うにはどんな作業が必要か調べるため、実際に環境を作って調べてみました。
- 検証作業の流れ
- 構成図
- Transit Gateway の共有の作成
- 共有先アカウントでの共有の受け入れ
- Transit Gateway ルートテーブルへの経路情報の伝搬
- VPC ルートテーブルへの Transit Gateway への経路情報を追加
- 疎通確認
- まとめ
- 参考
検証作業の流れ
- 2 つの AWS アカウント(アカウント A、B とします)を用意し、それぞれのアカウントで、東京リージョンにプライベートサブネットのみ持つ VPC を一つずつ作成。各 VPC に検証用の EC2 インスタンスを一つ立てる。
- アカウント A に Transit Gateway (TGW) を作成。
- アカウント A の VPC のプライベートサブネットから TGW に接続するアタッチメントを作成。
- アカウント A の Resource Access Manager (RAM) でアカウント B に TGW のリソース共有を招待。
- アカウント B の RAM でアカウント A からの TGW のリソース共有の招待を承認する。
- アカウント B で、アカウント B の VPC のサブネットから共有された TGW に接続するアタッチメントを作成。
- アカウント A でアカウント B の TGW アタッチメントを承諾。
- 各 TGW アタッチメントから TGW ルートテーブルに経路情報を伝搬させ、各 VPC のルートテーブルにも TGW への経路情報を追加。
- 互いの VPC の EC2 同士でネットワークが疎通することを確認する(今回のゴール)。
構成図
今回の検証作業で作る AWS 環境の構成図は次の通りです。

Transit Gateway の共有の作成
共有元アカウントで Transit Gateway の作成
アカウント A の VPC のマネジメントコンソールで「Transit Gateway」から「Transit Gateway を作成」をします。「デフォルトルートテーブルの関連付け」と「共有アタッチメントを自動承諾」は、後で手動で確認したいため、敢えてオフにします。

Transit Gateway アタッチメントの作成
同じくアカウント A のマネジメントコンソールの「Transit Gateway アタッチメント」から「Transit Gateway アタッチメントを作成」をします。TGW アタッチメントは VPC のサブネットと関連付けします。

Transit Gateway ルートテーブルの作成
同じくアカウント A のマネジメントコンソールの「Transit Gateway ルートテーブル」から「Transit Gateway ルートテーブルを作成」をします。ここでは経路情報はまだ作成しません。後で TGW に接続するアタッチメントから経路情報を伝搬させることで経路情報を自動作成するようにしたいと思います。

Resource Access Manager で Transit Gateway を別アカウントへリソース共有
Transit Gateway の共有には Resource Access Manager を使います。なお、通常マルチアカウントで AWS 環境を運用する場合、Organizations で統合管理するのがベストプラクティスで、RAM を使う場合も組織でリソース共有を管理するべきと思いますが、残念ながらガバメントクラウドでは自治体側で Organizations を管理できないようなので、個別にリソース共有を作成していく必要があると思われます。
共有元のアカウントでリソース共有を作成
アカウント A の Resource Access Manager のマネジメントコンソールで、「リソース共有」から「リソース共有の作成」をします。
先に作成した Transit Gateway を選択します。

Transit Gateway のマネージド型アクセス許可があるのでそれを使用します。

共有させたいアカウント B の AWS アカウント ID を選択します。

「リソース共有を作成」します。


共有先アカウントでの共有の受け入れ
共有先のアカウントでリソース共有を承認
今度はアカウント B 側の Resource Access Manager のマネジメントコンソールにアクセスします。「リソースの共有」から、先の手順でアカウント A で作成した Transit Gateway のリソース共有が保留状態になっていることが確認できます。

「リソース共有を承認」することで、アカウント B からアカウント A が共有した Transit Gateway を使用できるようになります。

共有先アカウントからの Transit Gateway アタッチメントの作成
アカウント A 側と同様に、アカウント B のマネジメントコンソールから Transit Gateway アタッチメントを作成します。
共有元のアカウントでアタッチメントの承認
アカウント A 側のマネジメントコンソールに戻り、「VPC」から「Transit Gateway アタッチメント」を選択します。アカウント B で作成したアタッチメントの状態が「Pending Acceptance」となっており、共有元のアカウント A 側に承認されるのを待っている状態であることが分かります。

「アクション」から「アタッチメントを承諾」をします。

これで両アカウントの VPC のプライベートサブネットが Transit Gateway アタッチメントを通じてアカウント A の TGW に接続されました。しかし、必要な経路情報(ルーティングテーブル)がないため、まだ互いのプライベートサブネット同士はネットワーク的には疎通していません。
それでは互いのプライベートサブネット同士のネットワークの疎通に必要な経路情報を作成していきます。
Transit Gateway ルートテーブルへの経路情報の伝搬
Transit Gateway ルートテーブルを作成し、TGW アタッチメントで接続する VPC のサブネットへの経路情報を追加することで、TGW 経由でのルーティングが可能になります。ここで、経路情報を静的に手動追加することもできますが、TGW アタッチメントからサブネットの情報を伝搬することで、そのサブネットへの経路情報を自動的に TGW ルートテーブルへ追加することができるのでこちらがお勧めです。
Transit Gateway ルートテーブルと TGW アタッチメントの関連付け
既にアカウント B の Transit Gateway アタッチメントを承諾しているため、以降の作業は全てアカウント A のマネジメントコンソールで行います。
まずは TGW ルートテーブルと TGW アタッチメントを関連付けます。VPC のマネジメントコンソールの「Transit Gateway ルートテーブル」から、先に作成した TGW ルートテーブルを選び、「関連付けを作成」をします。アカウント A アカウント B 両方の TGW アタッチメントを関連付けます。

両方の TGW アタッチメントが関連付けられたことを確認します。

Transit Gateway ルートテーブルへの TGW アタッチメントからの経路情報の伝搬
関連付けの作成と同じような手順で「伝搬を作成」をします。アカウント A アカウント B 両方の Transit Gateway アタッチメントから経路情報を伝搬するようにします。

両方の TGW アタッチメントからの伝搬が有効になったことを確認します。
Transit Gateway ルートテーブルの確認
伝搬が有効になると、Transit Gateway ルートテーブルに、それぞれの TGW アタッチメントから伝搬された経路情報が自動的に追加されます。

VPC ルートテーブルへの Transit Gateway への経路情報を追加
互いの VPC のルートテーブルに、互いのサブネットへのネクストホップが Transit Gateway であるという経路情報を追加します。これは各アカウントのマネジメントコンソールでそれぞれ作業します。

これで互いの VPC のプライベートサブネット間をルーティングするために必要な経路情報が全て設定されました。
疎通確認
最後に互いの VPC にある EC2 同士で Ping などで疎通確認します。手順は省略しましたが、互いのサブネットのセキュリティグループに検証用の通信を許可する設定を入れ忘れないよう注意しましょう。
まとめ
以上がマルチアカウントの閉域 VPC を Transit Gateway で相互接続する手順となります。
ポイントは、
- Transit Gateway を Resource Access Manager でアカウント間の共有をすること。
- 別アカウントの TGW に TGW アタッチメントを接続するには、TGW のあるアカウント側で TGW アタッチメントを承諾すること。
- TGW ルートテーブルに TGW アタッチメントを関連させ、更に経路情報を伝搬させること。
- VPC ルートテーブルに TGW への経路情報を追加すること。
になるかと思います。アカウント間で連携して作業が必要になるため、アカウントを運用管理補助するベンダが異なるマルチベンダの場合は、ベンダ間の調整を自治体が自分でやるか統合運用管理補助者を委託しているのであればそこへ依頼するか、いずれかの対応が必要になるかと思います。
ちなみに検証用の TGW(TGW アタッチメント)もそこそこお金がかかるので、検証を終えたら削除することをお勧めします。今回の検証環境の場合、1 か月で大体以下の通りの金額になるかと思います。
TGW アタッチメント 1 つ当たり 0.07USD * 24 時間 * 30 日間 = 50.4USD * 2 個 = 100.8USD = 16,128 円(1 ドル 160 円換算)
参考
また、この検証作業で作成したマルチアカウント間のプライベートサブネットの相互接続環境を使って、オブジェクトストレージの共有、Route 53 名前解決の共有を検証した記事を書いていますので、良ければこちらも参考にしてください。
ガバメントクラウドを想定したマルチアカウント間の Route 53 プライベートホストゾーンとインバウンドエンドポイントの共有について
地方自治体が使うガバメントクラウドの内、AWS で構築する環境については、本番環境アカウント、検証環境アカウント、ネットワークアカウントなど、複数の AWS アカウントで運用されることが多く、特に一つの自治体が複数のベンダ(マルチベンダ)に AWS 環境を構築してもらう場合、一つの自治体の AWS 環境の中に複数のアカウント(マルチアカウント)が運用されることは珍しくありません。
ここで、AWS 環境での名前解決には Route 53 を使うことが一般的で、地方自治体がガバメントクラウドとして AWS 環境の名前解決(DNS)を考える時は、閉域ネットワークであるという特性上、オンプレミス(庁内ネットワーク)と AWS 環境の DNS の連携のため、VPC にインバウンドエンドポイントを置くことがほぼ必須となります。
また、マルチベンダの場合、各アカウントの運用管理補助者となるベンダが異なるため、Route 53 のプライベートホストゾーンは各アカウント側で管理したいという要望もあると思います。
プライベートホストゾーンを各アカウントで管理してもそこまで AWS の料金はかかりませんが、インバウンドエンドポイントの料金はそこそこいいお値段(エンドポイント 1 つにつき 1 時間当たり 0.125USD。1 ドル 160 円とすると 1 か月で約 90 USD = 14,400 円。エンドポイントは最低 2 個以上要るので 28,800 円程度。)となります。そのため、庁内ネットワークからの名前解決のために各アカウントの VPC でそれぞれ Route 53 のインバウンドエンドポイントを置くとすると、コストがかかってしまいますし、管理工数もばかになりません。
そこで、ガバメントクラウドのような閉域の AWS 環境でかつマルチアカウント運用の名前解決を考える場合で、マルチアカウントの VPC 間が Transit Gateway などでネットワークが繋がっている場合は、以下のような Route 53 の運用が効率的かと思います。
- Route 53 インバウンドエンドポイントは、各 VPC と相互接続する共通用 VPC にのみ設置し、庁内ネットワーク及び各 VPC からはルーティングで Route 53 インバウンドエンドポイントにアクセスさせる。
- 各アカウントで管理するプライベートホストゾーンは、上記の共通用 VPC に関連付けし、共通用 VPC の Route 53 インバウンドエンドポイントで名前解決できるようにする。
この Route 53 の設定を試すため、個人の AWS 環境で次の通り検証してみました。
- 前提条件
- 検証環境の構成図
- マルチアカウント間のプライベートホストゾーンの関連付け
- インバウンドエンドポイントの作成
- アカウント B の EC2 からアカウント A の VPC のインバウンドエンドポイントで名前解決する
- インバウンドエンドポイントの削除
- まとめ
- 参考
前提条件
- 2 つの AWS アカウント(アカウント A、B とします)で、それぞれ東京リージョンにプライベートサブネットのみの VPC を一つずつ作成する。また、それぞれの VPC に一つずつ検証用の EC2 を立てる。
- 2 つの AWS アカウントに、それぞれ別のサブドメインで Route 53 のプライベートホストゾーンを作成し、それぞれのプライベートホストゾーンには、自アカウントの EC2 の A レコードのみ登録する。
- 2 つの VPC は Transit Gateway で接続し、互いのサブネットへルーティングできるようにする。
- アカウント B のプライベートホストゾーンをアカウント A の VPC に関連付け、アカウント A の EC2 でアカウント B のプライベートホストゾーンの A レコードを引けるようにする(1 つめのゴール)。
- アカウント A の VPC に Route 53 インバウンドエンドポイントを作成し、アカウント B の EC2 からインバウンドエンドポイントを指定して名前解決することでアカウント A のプライベートホストゾーンの A レコードを引けることを確認する(2 つめのゴール)。
検証環境の構成図
構成図を簡単にまとめました。
VPC の作成、EC2 の作成、Systems Manager のエンドポイントを作成して Session Manager 経由での閉域 EC2 へのアクセス、Transit Gateway の接続の手順は省略します。これは別途改めて記事にしたいと思います。
(2024/11/30 追記)Transit Gateway の接続方法、Session Manager の記事も書きました。
マルチアカウント間のプライベートホストゾーンの関連付け
プライベートホストゾーンの作成
アカウント A の Route 53 のマネジメントコンソールから「ホストゾーン」→「ホストゾーンの作成」から、プライベートホストゾーンを作成します。適当なサブドメイン(test01.intra.morori.jp)で作成しました。

関連付けるアカウント A の VPC を選択します。

アカウント A の VPC の EC2 の IP アドレスをプライベートホストゾーンに A レコードで登録します。

同様の手順でアカウント B にもプライベートホストゾーン(test02.intra.morori.jp)を作成しておきます。

アカウント B のプライベートホストゾーンはこのような状態になりました。

プライベートホストゾーンの作成が終わったら、それぞれのアカウントの EC2 にログインし、登録した A レコードを名前解決できるか確認します。

当然まだプライベートホストゾーンの関連付けをしていないので、名前解決できるのは自分のアカウントのプライベートホストゾーンのレコードのみです。
アカウント B のプライベートホストゾーンをアカウント A の VPC に関連付ける
アカウント B のプライベートホストゾーンのレコードをアカウント A の EC2 から名前解決できるよう、アカウント B のプライベートホストゾーンをアカウント A の VPC に関連付けます。これはマネジメントコンソールからでは操作できないため、AWS CLI で実施することにします。
関連付けの許可設定
まずはアカウント B のプライベートホストゾーンを、アカウント A の VPC に関連付ける許可設定をします。コマンドは以下の通りで、成功したら JSON が返ってきます。

コマンドの詳細は公式のドキュメントを参照。
関連付けの適用
今度はアカウント A の VPC に実際にアカウント B のプライベートホストゾーンを関連付けます。コマンドは以下の通りで、同様に JSON が返ってきます。

AWS CLI の操作は以上で完了です。マネジメントコンソールを見ると関連付けられた VPC が追加されていることが分かります。

アカウント A の EC2 からアカウント B のプライベートホストゾーンの A レコードを引けるか確認
アカウント A の EC2 にログインして、アカウント B の EC2 の A レコード(test02.test02.intra.morori.jp)を引けるか確認します。

関連付けたプライベートホストゾーンの A レコードが返ってきました!一つ目のゴールはクリアです。
ここで、逆にアカウント B の EC2 からアカウント A のプライベートホストゾーンのレコードは引けないことを確認しておきます。アカウント A のプライベートホストゾーンをアカウント B の VPC に関連付けは今回していないので、当然名前解決は失敗します。

この状態で、アカウント A に Route 53 インバウンドエンドポイントを作成し、アカウント B の EC2 がインバウンドエンドポイントを使って名前解決すれば、アカウント A のプライベートホストゾーンのレコードが引けるようになるか、確認します。
インバウンドエンドポイントの作成
アカウント A のマネジメントコンソールから、Route 53 のインバウンドエンドポイントを作成していきます。
初めに注意!
上記の通り、Route 53 インバウンドエンドポイントは料金が高いので、検証した後は速やかに削除しましょう。放っておくと、ひと月で 3 万円近くかかってしまいます。
セキュリティグループの作成
インバウンドエンドポイントに適用するセキュリティグループを事前に作ります。検証用のため、全ての範囲から TCP 及び UDP 53 番ポートへの通信を許可するルールを作ります。詳細は割愛。
インバウンドエンドポイントの作成
Route 53 のマネジメントコンソールから、「インバウンドエンドポイント」→「インバウンドエンドポイントの作成」に進みます。注意点として、インバウンドエンドポイントの作成には異なる AZ に跨る 2 つ以上の IP アドレスが必要なため、VPC には 2 つ以上の AZ のサブネットが必要です。


インバウンドエンドポイントの IP アドレスが作成されました。

アカウント B の EC2 からアカウント A の VPC のインバウンドエンドポイントで名前解決する
ここまで来たら最後です。アカウント B の EC2 にログインし、アカウント A の Route 53 インバウンドエンドポイントを指定してアカウント A の EC2 の A レコード(test01.test01.intra.morori.jp)を引いてみます。

レコードが返ってきました!これで二つ目のゴールもクリアです。
インバウンドエンドポイントの削除
料金が高いため、インバウンドエンドポイントは速やかに削除しましょう。
まとめ
以上でマルチアカウント間でプライベートホストゾーンとインバウンドエンドポイントを共有する方法について検証できました。本当はオンプレから VPC に VPN で接続してオンプレからもインバウンドエンドポイントで名前解決できるか試したかったのですが、VPN は料金的に簡単にはできない感じなので諦めました……。
AWS 環境の名前解決は非常に重要ですので、運用が楽でかつコストメリットのある方法を採用するのがよいと思います。
参考
ガバメントクラウドを想定した閉域かつ複数アカウントから S3 を共有する方法を考える(ゲートウェイエンドポイント・インターフェイスエンドポイント)
ガバメントクラウドを活用した標準準拠システム同士のデータ連携はオブジェクトストレージによるファイル連携となっています。
ここで、ガバメントクラウドの CSP に AWS を選択した場合で、データ連携用オブジェクトストレージとして S3 を共有する方法を考えてみたいと思います。
なお、ガバメントクラウド上の標準準拠システムからオブジェクトストレージへのアクセスは閉域が要件となるため、以下の 2 パターンのエンドポイント経由で S3 へアクセスする必要があると考えています。
ゲートウェイエンドポイントとインターフェイスエンドポイントの違いは以下の記事が分かりやすかったです。
また、標準準拠システムがマルチベンダ体制で構築されていることを想定し、複数アカウント間で S3 を共有できるようにします。
検証環境の準備
検証環境として、以下のような構成を作ります。

VPC の作成
AWS アカウントを 2 つ用意し、それぞれのアカウントに VPC を 1 つずつ作成します。
閉域とするため、各 VPC にはパブリックサブネットは作らず、プライベートサブネットを 1 つずつ作ります(検証目的なので AZ も 1 つです。)。
EC2 の作成
プライベートサブネットには、EC2(t4g.nano の Amazon Linux 2023) を 1 つずつ配置します。このパブリックなネットワークへ出られない EC2 インスタンスから、S3 にゲートウェイエンドポイント、インターフェイスエンドポイントそれぞれを経由してアクセスできるか試してみます。
プライベートサブネットの EC2 を操作するため、Systems Manager の Session Manager 機能を使います。Systems Manager は、プライベートサブネットからでも、Systems Manager のエンドポイントを作ることで使用することができます(料金がかかるので要注意)。
Session Manager が EC2 と疎通したら、Session Manager の上に SSH を通します。以降は SSH で EC2 を操作します。
EC2 を Ubuntu のクライアントから SSH したかったので、クライアント側には Session Manager のプラグインをインストールしました。また、この AWS 環境は AWS IAM Identity Center のユーザーで SSO できるので、AWS CLI から SSO する設定をしておきました。
EC2 に SSH で接続できるようになったら、EC2 から S3 へのアクセスを確認するために、EC2 に AWS CLI をインストールします。
Transit Gateway の作成
最後に互いの VPC 間で閉域通信できるようルーティングの設定をします。
今回検証する VPC は 2 つなので、VPC 間の通信は VPC Peering でもいいのですが、せっかくガバメントクラウドを想定するので、Transit Gateway (TGW) を作成し、各 VPC に TGW アタッチメントを作成します(料金がかかるので要注意)。
各 VPC は別アカウントにあるため、TGW は一方のアカウント側で作成し、もう一方のアカウントと Resource Access Manager (RAM) で TGW を共有し、アカウントを跨いでアタッチメントを承認することになります。
余談ですがこの作業はガバメントクラウドのネットワーク運用管理補助者に求められると思います。
TGW ルートテーブルと各 VPC のルートテーブルに互いのサブネット宛てのルートを正しく設定したら、EC2 同士で疎通ができるかを確認し、OK だったら準備完了です。
S3 のゲートウェイエンドポイント
自身のアカウントの S3 に対するゲートウェイエンドポイント経由でのアクセス
片方のアカウント(アカウント A とします)で適当な名前の S3 バケットをパブリックアクセスを全てブロックの設定で作成し、適当なファイルをアップロードしておきます。
この時点では、アカウント A の VPC にある EC2 から S3 へはアクセスできません(プライベートサブネットに EC2 があるため)。
そこで、アカウント A の VPC に S3 ゲートウェイエンドポイントを作成します。
マネジメントコンソールの VPC のメニューからエンドポイントを選び、「AWS のサービス」からタイプが「Gateway」の S3 のサービス名を選び、作成する VPC と紐づけるルートテーブルを選んで作成するだけです。作成すると自動的に S3 ゲートウェイエンドポイントへのルートが追加されます。

ゲートウェイエンドポイントが作成できたら、アカウント A の EC2 に SSH で入って、AWS CLI からアカウントA の S3 バケットのファイルの一覧を取得してみます。
![]()
プライベートサブネットの EC2 から S3 へアクセスできることが確認できました。
別のアカウントの S3 に対するゲートウェイエンドポイント経由でのクロスアカウントアクセス
同じ手順でもう一方のアカウント(アカウント B とします)にも S3 ゲートウェイエンドポイントを作成します。
アカウント B の EC2 からアカウント A の S3 バケットにアクセスしても、この時点ではアクセスを拒否されてしまいます。

そこで、アカウント A の S3 バケットに、アカウント B の特定の IAM ロールのみ許可するバケットポリシーを設定します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Allow-access-to-specific-IAMRole", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::(AccountB_AWS_ACCOUNT_ID):role/test01-dev-app-role" }, "Action": [ "s3:PutObject", "s3:GetObject", "s3:DeleteObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::test02-dev-gateway-hogehoge", "arn:aws:s3:::test02-dev-gateway-hogehoge/*" ] } ] }
このバケットポリシーの Principal に設定したアカウント B の IAM ロールをアタッチした EC2 から、アカウント A の S3 バケットにアクセスできるようになりました。
![]()
S3 のインターフェイスエンドポイント
今度はインターフェイスエンドポイントを試してみます。インターフェイスエンドポイントを作成すると、エンドポイントにプライベート IP アドレスが付与され、Transit Gateway で接続された別の VPC からルーティングしてエンドポイントにアクセスできる想定です。
検証しやすいよう、上記で作成したものとは別の S3 バケットをアカウント A に作成しておきます。
アカウント A のマネジメントコンソールの VPC のメニューからエンドポイントを選びます。今度はタイプが「Interface」となっている S3 のサービス名を選択します。ゲートウェイエンドポイント作成の時との違いは、エンドポイントを作成するサブネットを選び、セキュリティグループをアタッチすることです。このセキュリティグループには、HTTPS を許可するルールが必要です。

インターフェイスエンドポイントができたら、先ほど作成した S3 バケットに、上記と同様に特定の IAM ロールのみ操作を許可するバケットポリシーを作成します。
S3 のバケットポリシーの設定が終わったら、アカウント B の EC2 から AWS CLI で、インターフェイスエンドポイントを指定して S3 にアクセスしてみます。指定方法は、インターフェイスエンドポイントに割り振られた固有の DNS 名になります(実際の運用ではプライベート DNS 名を管理してこれでアクセスさせると思いますが、今回は検証なのでインターフェイスエンドポイント固有の DNS 名を使います。)。
なお、インターフェイスエンドポイント固有の DNS 名はマネジメントコンソールから確認できます。

想定通り、Transit Gateway でルーティング可能な別 VPC から、別 VPC のインターフェイスエンドポイント経由で S3 へアクセスできることが確認できました。

インターフェイスエンドポイントのセキュリティ対策
インターフェイスエンドポイントの正体は ENI のため、セキュリティグループで送信元 IP アドレスに基づく制限が可能です。また、VPC エンドポイントポリシーでの制限もできます。 インターフェイスエンドポイントを経由する場合のみアクセスを許可するバケットポリシーを設定すれば、今回の要件だと閉域内からのアクセスのみに限定することができるかと思います。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Access-to-specific-VPCE-only", "Effect": "Allow", "Principal": "*", "Action": [ "s3:PutObject", "s3:GetObject", "s3:DeleteObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::test02-dev-interfaceonly-hogehoge", "arn:aws:s3:::test02-dev-interfaceonly-hogehoge/*" ], "Condition": { "StringEquals": { "aws:SourceVpce": "vpce-fugafuga" } } } ] }
ではガバメントクラウドではどちらのエンドポイントを採用すべきか?
恐らく以下のような基準でいいのではないでしょうか?
- オンプレミスや別リージョンの VPC からファイル連携 S3 にアクセスさせたい場合、ファイル連携 S3 のあるアカウントの VPC にインターフェイスエンドポイントを作り、Transit Gateway 経由でアクセスさせる。
- そうでなければ、各アカウントの VPC にゲートウェイエンドポイントを作らせ、それぞれのゲートウェイエンドポイント経由でアクセスさせる。
インターフェイスエンドポイントは費用がかかるため、ゲートウェイエンドポイントでいい要件であればゲートウェイエンドポイントで良いと思います。
ただ、インターフェイスエンドポイントはセキュリティグループなどでも制限が可能なので、こちらの方がよりセキュリティが高いように思える(バケットポリシーで万が一オペミスしても外部からアクセスされることはない)のですが、識者の意見を聞きたいところです。
最後に S3 のセキュリティ対策で参考になったリンクです。
Squidで特定ドメインまたはURLの場合のみ上位プロキシを通し、それ以外は上位プロキシを通さない振り分け設定
Squidで特定のドメインの場合は指定した上位プロキシ経由でアクセスし、それ以外は上位プロキシを通さず自身でアクセスするようにする設定です。また、アクセス方法がHTTPSでなく平文のHTTPである場合のみ、特定のURLで振り分けることも可能です。
クラウドの業務システム向け通信は上位プロキシ、それ以外のインターネット向け通信は全て自プロキシ、といったことが実現できます。
検証はSquidのバージョン3.5で行っています。
なお、多段プロキシ構成で特定ドメインまたはURLで上位プロキシを振り分ける設定の場合は以下のページにまとめています。
概要
- cache_peerに上位プロキシを定義。
- aclに振り分けたい特定ドメインを定義。
- cache_peer_accessに振り分けたい特定ドメインを定義したaclと経由したい上位プロキシを定義したcache_peerを紐付け。
- never_direct allow acl_name, always_direct deny acl_name, always_direct allow allを記載すると、aclに当てはまらない通信は全て上位プロキシを経由せず自身でアクセスするようになる。
設定例
構成
多段プロキシ構成は以下の通りとします。上位プロキシには振り分けに関する設定は不要で、全て下位プロキシ側に設定することになります。
| プロキシサーバ | ホストと待受けポート |
|---|---|
| Aプロキシ(特定ドメインまたはURLの場合経由させたい上位プロキシ) | system-proxy.example.com:3128 |
| Bプロキシ(クライアント側に設定しているプロキシ〔下位プロキシ〕) | client-proxy.example.com:8080 |
下位プロキシ側(Bプロキシ)の設定
コンフィグ例
/etc/squid/squid.confに以下の通り追記(または変更)します。
# 上位プロキシの定義 # Aプロキシ(特定ドメインまたはURLの場合経由させたい上位プロキシ) cache_peer system-proxy.example.com parent 3128 0 no-query # 振り分けたい特定ドメイン・URLの定義 # 振分け対象ドメイン acl system-domain dstdomain "/etc/squid/system-domain.acl" # 振り分け対象URL(ただしHTTPSだとURLで振り分けることはできないのでドメインで振り分けるしかない) acl system-url url_regex "/etc/squid/system-url.acl" # 振分け対象特定ドメイン・URLとAプロキシの紐付け cache_peer_access system-proxy.example.com allow system-domain cache_peer_access system-proxy.example.com allow system-url # 振分け対象特定ドメイン・URL以外は全てBプロキシ(自分自身)経由にする never_direct allow system-domain never_direct allow system-url always_direct deny system-domain always_direct deny system-url always_direct allow all
ポイントは、
- never_direct allowとalways_direct denyの両方にACLをセットで設定する必要があること。
- 最後にalways_direct allow allをすること。
です。
振分け対象ドメインの指定
振り分けたい特定ドメインをここではsystem-domainという名前(名前は任意で大丈夫)のaclに定義しています。
acl system-domain dstdomain "/etc/squid/system-domain.acl"
dstdomainの後に対象ドメインをベタ書きしてもいいのですが、メンテしやすいよう/etc/squid/system-domain.aclというテキストファイルを作成し、対象ドメインを列記するようにします。
/etc/squid/system-domain.aclの内容は次の通りです。振り分けたい特定ドメインがsystem01.example.comというドメインと、system02.example.comのサブドメインという想定です。
system01.example.com .system02.example.com
振分け対象URLの指定
同様に、振り分けたい特定URLをsystem-urlという名前のaclに定義しています。/etc/squid/system-url.aclというテキストファイルを作成し、対象URLを列記するようにします。
acl system-url url_regex "/etc/squid/system-url.acl"
ポイントは、aclのurl_regexは対象URLを正規表現で記載できることです。dstdomainの方は正規表現は使えないので注意です。
ただし、HTTPSの場合はURLでの振分けは使えません。後で検証の際にSquidのaccess.logを見れば分かるのですが、HTTPSの場合、クライアントと通信先サーバとの間で暗号化されているので参照先URLがSquidからは見えないためだと思われます。
/etc/squid/system-url.aclの内容は次の通りです。振り分けたい特定URLがhttp://system03.example.com/maintener/以下という想定です。
^http://system03\.example\.com/maintener/.*$
設定の反映
コンフィグに誤りがないことが確認できたら、Bプロキシのsquidサービスをリロード(または再起動)します。
# systemctl reload squid
振分けができているか確認
期待した通りに振分け設定ができていれば、Bプロキシのaccess.logには次のようなログが出力されます。
651285320.368 1663 198.51.100.123 TCP_TUNNEL/200 3878 CONNECT system01.example.com:443 - FIRSTUP_PARENT/192.0.2.1 -
上位プロキシ側は次のようなログが出力されます。
651285320.370 1441 192.0.2.1 TCP_TUNNEL/200 3139 CONNECT system01.example.com:443 - HIER_DIRECT/203.0.113.200 -
Squidの多段プロキシ構成で特定ドメインまたはURLで上位プロキシを振り分ける設定
Squidで多段プロキシ構成で複数の上位プロキシが存在している時に、特定のドメインの場合は指定した上位プロキシ経由でアクセスするようにする設定です。また、アクセス方法がHTTPSでなく平文のHTTPである場合のみ、特定のURLで振り分けることも可能です。
クラウドの業務システム向け通信はAプロキシ、それ以外のインターネット向け通信は全てBプロキシ、といったことが実現できます。
検証はSquidのバージョン3.5で行っています。
概要
- cache_peerに上位プロキシを定義。この時デフォルトのプロキシは必ず他の上位プロキシを定義する行より下に記載しないとならない。
- aclに振り分けたい特定ドメインを定義。
- cache_peer_accessに振り分けたい特定ドメインを定義したaclと経由したい上位プロキシを定義したcache_peerを紐付け。
- never_direct allow allを記載すると、aclに当てはまらない通信は全てデフォルトの上位プロキシを経由するようになる。
設定例
構成
多段プロキシ構成は以下の通りとします。上位プロキシには振り分けに関する設定は不要で、全て下位プロキシ側に設定することになります。
| プロキシサーバ | ホストと待受けポート |
|---|---|
| Aプロキシ(特定ドメインまたはURLの場合経由させたい上位プロキシ) | system-proxy.example.com:3128 |
| Bプロキシ(それ以外の場合経由させたいデフォルトの上位プロキシ) | internet-proxy.example.com:3128 |
| Cプロキシ(クライアント側に設定しているプロキシ〔下位プロキシ〕) | client-proxy.example.com:8080 |
下位プロキシ側(Cプロキシ)の設定
コンフィグ例
/etc/squid/squid.confに以下の通り追記(または変更)します。
# 上位プロキシの定義 # Aプロキシ(特定ドメインまたはURLの場合経由させたい上位プロキシ) cache_peer system-proxy.example.com parent 3128 0 no-query # Bプロキシ(それ以外の場合経由させたいデフォルトの上位プロキシ) # デフォルトのプロキシは必ず他の上位プロキシより下の行に書くこと! cache_peer internet-proxy.example.com parent 3128 0 default no-query # 振り分けたい特定ドメイン・URLの定義 # 振分け対象ドメイン acl system-domain dstdomain "/etc/squid/system-domain.acl" # 振り分け対象URL(ただしHTTPSだとURLで振り分けることはできないのでドメインで振り分けるしかない) acl system-url url_regex "/etc/squid/system-url.acl" # 振分け対象特定ドメイン・URLとAプロキシの紐付け cache_peer_access system-proxy.example.com allow system-domain cache_peer_access system-proxy.example.com allow system-url # 振分け対象特定ドメイン・URL以外は全てBプロキシ経由にする never_direct allow all
解説
上位プロキシの設定
ここで重要なのが、デフォルトの上位プロキシを指定する記載は必ず他の上位プロキシを指定する行より後にする必要があることです。defaultというキーワードを指定していてもなぜか関係ありません。他の上位プロキシの記載が後にあるとそちらがデフォルトになってしまい、意図した通りになりません。
cache_peer system-proxy.example.com parent 3128 0 no-query cache_peer internet-proxy.example.com parent 3128 0 default no-query # こちらがデフォルトの上位プロキシ
Squidのドキュメントを読んでも、複数のdefaultを指定した上位プロキシがある場合は最初のものが使われる、との記述があるも、実際にコンフィグに投入しても意図した通りにはなりませんでした。また、cache_peer自体の順序についても記述はありません。ですが実際には一番最後に指定したcache_peerがデフォルトになってしまうので、cache_peerの記述順序は要注意です。
==== PEER SELECTION METHODS ====
The default peer selection method is ICP, with the first responding peer being used as source. These options can be used for better load balancing.
default This is a parent cache which can be used as a "last-resort" if a peer cannot be located by any of the peer-selection methods. If specified more than once, only the first is used.
http://www.squid-cache.org/Versions/v3/3.5/cfgman/cache_peer.html
振分け対象ドメインの指定
振り分けたい特定ドメインをここではsystem-domainという名前(名前は任意で大丈夫)のaclに定義しています。
acl system-domain dstdomain "/etc/squid/system-domain.acl"
dstdomainの後に対象ドメインをベタ書きしてもいいのですが、メンテしやすいよう/etc/squid/system-domain.aclというテキストファイルを作成し、対象ドメインを列記するようにします。
/etc/squid/system-domain.aclの内容は次の通りです。振り分けたい特定ドメインがsystem01.example.comというドメインと、system02.example.comのサブドメインという想定です。
system01.example.com .system02.example.com
振分け対象URLの指定
同様に、振り分けたい特定URLをsystem-urlという名前のaclに定義しています。/etc/squid/system-url.aclというテキストファイルを作成し、対象URLを列記するようにします。
acl system-url url_regex "/etc/squid/system-url.acl"
ポイントは、aclのurl_regexは対象URLを正規表現で記載できることです。dstdomainの方は正規表現は使えないので注意です。
ただし、HTTPSの場合はURLでの振分けは使えません。後で検証の際にSquidのaccess.logを見れば分かるのですが、HTTPSの場合、クライアントと通信先サーバとの間で暗号化されているので参照先URLがSquidからは見えないためだと思われます。(SquidでHTTPSを終端するようなman in the middle的設定ができるなら可能なのかも。)
そのため、HTTPSの場合はURLでの振分けは諦めて、ドメインで振り分けるしかなさそうです。
/etc/squid/system-url.aclの内容は次の通りです。振り分けたい特定URLがhttp://system03.example.com/maintener/以下という想定です。
^http://system03\.example\.com/maintener/.*$
ちなみにHTTPS(標準ポート)でドメインの振分けで正規表現が使いたい場合は、dstdomainでは正規表現が使えないためurl_regexを使って次のような書き方ができると思います。
# HTTPSで正規表現を使ったドメイン振り分け例(dstdomainではできないことに注意) ^branch[0-9]+\.system03\.example\.com:443$ # HTTPもある場合を想定した書き方 ^(http://)*branch[0-9]+\.system03\.example\.com(:443)*(/.*)*$
指定以外の通信は全てデフォルトの上位プロキシに向ける設定
最後に以下の記述がないと下位プロキシが上位プロキシを経由せず直接通信してしまいます。
never_direct allow all
設定の反映
コンフィグに誤りがないことが確認できたら、Cプロキシのsquidサービスをリロード(または再起動)します。
# systemctl reload squid
振分けができているか確認
期待した通りに振分け設定ができていれば、Cプロキシのaccess.logには次のようなログが出力されます。
651285320.368 1663 198.51.100.123 TCP_TUNNEL/200 3878 CONNECT system01.example.com:443 - FIRSTUP_PARENT/192.0.2.1 -
上位プロキシ側は次のようなログが出力されます。
651285320.370 1441 192.0.2.1 TCP_TUNNEL/200 3139 CONNECT system01.example.com:443 - HIER_DIRECT/203.0.113.200 -
既存のHerokuで動かしているFlask + GunicornのアプリにNGINXのリバースプロキシを追加する方法 (Heroku Buildpack)
概要
- Heroku Buildpack: NGINX を使えばHerokuでNGINXを導入できるのでHerokuにデプロイしているアプリケーションにリバースプロキシを設置できる。
- アプリケーションのWebサーバがGunicornの場合、GunicornをUNIXソケットで待ち受けるように設定変更が必要。
- 基本的に Heroku Buildpack: NGINX の手順通りやれば動いた。サンプルにはWebサーバにRubyのUnicornを使う手順が記載されているが、適宜PythonのGunicornに置き換えれば大丈夫。アプリケーションはFlaskで動かしているが、DjangoでもGunicornを使うなら動くのではないかと思う。
きっかけ
旭川市新型コロナウイルスまとめサイト をGoogleの Page Speed Insights で計測したらモバイルページの点数が低かったので、リバースプロキシ入れてキャッシュ時間をコントロールすれば改善できると思ったから。しかしオチを先に書くと、自分の書いたnginx.confがしょぼいのか導入前後でスコアは変わらなかった。(たぶんHerokuってログに記録される送信元IPアドレスがローカルIPアドレスなところを見るとデフォルトでリバースプロキシ越しに最適化されてアクセスされるように設計されている?)
ちなみに最初DockerでGunicorn動かすコンテナとNGINX動かすコンテナ2つ動かせばいけるのかなと思ったのだけど、自分が調べた範囲ではHerokuだと無理っぽい。なので開発環境ではDocker ComposeでGunicorn + Flaskが動くApplicationコンテナとNGINXが動くWeb Serverコンテナを使い、Heroku上の本番環境ではHeroku BuildpackのNGINXを使うようにしている。
手順
GunicornをUNIXソケットで待ち受けるよう変更
アプリのルートディレクトリに次のような gunicorn.conf.py を配置し、Gunicorn起動時に -c オプションで gunicorn.conf.py を指定すれば、通常のTCPソケットで待ち受けるモードからUNIXソケットで待ち受けるモードに変更できる。
def when_ready(server): open("/tmp/app-initialized", "w").close() bind = "unix:///tmp/nginx.socket"
UNIXソケット通信で使うファイル名はHeroku Buildpacks: NGINXの仕様に合わせておく。
Requirements (Proxy Mode)
Your webserver listens to the socket at /tmp/nginx.socket.
You touch /tmp/app-initialized when you are ready for traffic.
You can start your web server with a shell command.
heroku/heroku-buildpack-nginx - Buildpacks - Heroku Elements
リバースプロキシで動かすためのNGINXの設定ファイルを作成
アプリのルートディレクトリに config ディレクトリを作成し、その中に nginx.conf.erb を作成する。Heroku Buildpack: NGINXの Githubリポジトリに nginx.conf.erb のサンプル があるのでこれをベースにお好みで設定する。
daemon off; worker_processes <%= ENV['NGINX_WORKERS'] || 4 %>; events { use epoll; accept_mutex on; worker_connections <%= ENV['NGINX_WORKER_CONNECTIONS'] || 1024 %>; } http { gzip on; gzip_comp_level 2; gzip_min_length 512; gzip_proxied any; server_tokens off; log_format l2met 'measure#nginx.service=$request_time request_id=$http_x_request_id'; access_log <%= ENV['NGINX_ACCESS_LOG_PATH'] || 'logs/nginx/access.log' %> l2met; error_log <%= ENV['NGINX_ERROR_LOG_PATH'] || 'logs/nginx/error.log' %>; include mime.types; default_type application/octet-stream; sendfile on; tcp_nopush on; keepalive_timeout 65; upstream app_server { server unix:///tmp/nginx.socket fail_timeout=0; } server { listen <%= ENV["PORT"] %>; location / { proxy_redirect off; proxy_pass http://app_server; } proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-Host $host; proxy_set_header X-Forwarded-Server $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } }
ちなみに nginx.conf.erb の設置パスに注意。Heroku Buildpacks: NGINXのページには次の通りSolo Modeの要求事項としてしか記載されていないが、Proxy Modeでも config/nginx.conf.erb に設置しないと読み込んでくれない。
Requirements (Solo Mode)
Add a custom nginx config to your app source code at config/nginx.conf.erb.
heroku/heroku-buildpack-nginx - Buildpacks - Heroku Elements
Heroku Buildpacks: NGINXのインストール
Heroku Toolbeltはインストール済みとする。ターミナルから次のコマンドでHeroku Buildpacks: NGINXを追加する。
heroku buildpacks:add heroku-community/nginx
Procfile の修正
Heroku Buildpacks: NGINXを使うには、アプリのルートディレクトリにある Procfile を修正する。
まず、動かしたいFlaskアプリがルートディレクトリにある次のような hello.py だとする。
from flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello, World!' if __name__ == "__main__": app.run()
これを普通にHerokuでWebサーバをGunicornで動かすには、以下のような Procfile になっていると思う。
gunicorn hello:app --log-file -
ここから、Procfile を次の通り変更する。
web: bin/start-nginx gunicorn hello:app -c gunicorn.conf.py --log-file=-
あとはHerokuの本番リポジトリに変更をPushすれば、NGINXのリバースプロキシ経由でGunicornにアクセスされるようになる。
感想
現状 Page Speed Insights はNGINX追加前後でスコアは変わらなかった。 旭川市新型コロナウイルスまとめサイト はUDフォントを使いたくてWebフォントを使っているし、FontAwsomeも使っているため、これでだいぶスコアが落ちてしまっているから仕方ないかもしれない。キャッシュを効かせるとしたら大きめのメディアファイルにだと思うのだけど、容量が大きいのがグラフの画像ファイルで、これは一応準リアルタイムで配信したいので、キャッシュ時間を10分に設定してみたがあまり効果なさそう。